
![]()
Contents
1 Introduction 5
1.1 Objectives 5
2 Company Requirements 6
2.1 Problems 6
2.2 Solutions 6
2.2.1 Business Justification 6
3 Database Design 8
3.1 Data Analysis 8
3.1.1 Objectives of the company 8
3.1.2 Branches 8
3.1.3 Staff 8
3.1.4 Properties 9
3.1.5 Owners 9
3.1.6 Clients/Renters 10
3.1.7 Summary 10
3.2 Conceptual Design 10
3.2.1 Attributes 10
3.2.2 Initial Relations 10
3.2.3 Normalized Relations 11
3.2.4 Entity Relationship Map 13
3.3 Data Dictionary 16
3.4 Transactions 19
3.5 Summary 19
4 Centralized Database System 20
4.1 Logical Design 21
4.1.1 Tables 21
4.1.2 Indexes 24
4.1.3 Queries and Transactions 25
4.1.4 Constraints on entering data 28
4.1.5 Constraints as assertions or triggers 28
4.2 Physical Design 30
4.3 Advantages 31
4.4 Disadvantages 31
4.5 Summary 31
5 Distribute Database System 32
5.1 Revised Design 32
5.2 Data Fragmentation 33
5.3 Data Replication 37
5.4 Data Allocation 37
5.5 Data Transparency 38
5.6 Advantages 39
5.7 Disadvantages 39
6 Object Oriented Database System 40
6.1 Initial Problem Statement 40
6.2 Object Identification 40
6.3 Class Identification 40
6.4 Relationship Identification and Modeling 41
6.5 Class Hierarchy 41
6.6 Class Definition 42
6.7 Schema Definition 43
6.8 Advantages 47
6.9 Disadvantages 47
6.10 Summary 47
7 Security 48
8 Backup and recovery 53
9 Costing 54
9.1 Economics 54
9.2 Hardware 55
9.2.1 Personal Computers 55
9.2.2 Servers/Workstations 56
9.2.3 Hubs 56
9.2.4 Routers 57
9.2.5 Miscellaneous 57
9.2.6 Printer 58
9.2.7 Printer Server 58
9.2.8 Total Costs 58
9.3 Software 59
9.3.1 Commercial 59
9.3.2 Total Costs 60
9.4 Staff Costs 60
9.5 Installation Plan 60
9.5.1 Hardware Requirements 61
9.5.2 Software Requirements 61
9.5.3 System Wide Requirements 61
9.5.4 Cost of Installation 61
9.6 Total Costs of each Design 61
9.7 Summary 62
10 Comparisons of three designs 63
10.1 Communication Costs 63
10.2 Locality of Reference 63
10.3 Reliability and Availability 64
10.4 Storage Costs 64
10.5 Performance 64
10.6 Other 65
11 Future Improvements 66
12 Conclusions 67
12.1 Our Strengths 67
13 Bibliography 68
1 Introduction
DreamHome is a property management organization, which specializes in the management of property for rent on behalf of the owners. Figure 1.1 below shows the organizational structure of DreamHome Co.
Each DreamHome branch office has a manager responsible for overseeing the operations of the office. Supervisors in each branch office are responsible for the day-to-day activities of a dedicated group of staff (5~10) responsible for the management of property for rent. The administrative work of each group of staff is supported by a secretary.
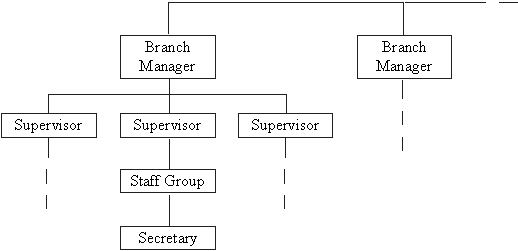
Figure 1.1
DreamHome Organizational Structure
The total number of staff employed by DreamHome is 300 split 90, 90 and 120 between Glasgow, Cardiff and London respectively.
1.1 Objectives
2 Company Requirements
The DreamHome company requirements are shown below and it is our job to solve these requirements to enable the company to run more efficiently and effectively.
2.1 Problems
Each branch is involved in the properties market but, there is no organization and connectivity between the branches. The current system is run manually therefore there are chances for properties not being recorded and stored in the proper fashion. For example, it may have been deleted, misplaced and so on. Some of DreamHome Company’s problems we aim to solve includes:
2.2 Solutions
Each DreamHome branch will have an update of all its current hardware and software and making sure that the branches are linked together via the WAN/LAN network. Factors such as determining who is dealing with what properties or the amount for the monthly bonus for mangers, finding details about a specific property can be determined more easily. This will enable the company to be more maintainable, effective and efficient. Below is some of the business justification of why we are proposing to install the computerized database system.
2.2.1 Business Justification
These factors should make the company more effective, efficient and more maintainable. Every branch will be able to communicate better.
This report done by us at DAC aims to show you DreamHome that there are several options where you can add a database system. We will show you the available options, compare these and provide you with a competitive costing on each of the designs. We will continue to work on each of the designs so you are kept up to date until you make a decision on which one to choose. The three database designs are as follows:
The next section describes the data analysis and general database design.
3 Database Design
This section describes the initial analysis of the data that is required to be stored and the conceptual design and schema.
3.1 Data analysis
We have analyzed the document provided by your company in order to determine what data is required to be stored. Below is an account of this based on the specification, and any assumptions made.
3.1.1 Objectives of company
The company’s main objectives is to provide properties for rent and to offer a service to owners.
3.1.2 Branches
The company has three branches situated in the UK therefore it would make sense to have a Branch entity to which all employees belong to and which will record details such as the total number of staff in each branch.
Assumptions
3.1.3 Staff
Each branch has a manager. The company follows the performance of the manager and requires the date that the manager was employed. The manager also has an annual car allowance and monthly bonus. Managers have some differences from ordinary staff members such as the monthly bonus scheme.
Each branch has supervisors who are responsible for a group of 5-10 other staff. The groups of staff are managed by a secretary. Every staff has a unique staff number. Based on these data requirements. We can see that there are several entities required such as Employee, Manager and a Group entity.
Assumptions
3.1.4 Properties
Properties are owned by owners and let out to renters by DreamHome. Therefore we would provide a property entity in which to record the details of the properties.
Assumptions
3.1.5 Owners
Owners may have one or many properties which are required to be rented out by the DreamHome company. Therefore they need to be associated with the properties that belong to them and have details recorded about the owners themselves. So a Owner entity is required in which to record these details.
Assumptions
3.1.6 Clients/Renters
Renters rent properties provided by the owners and have to be associated with the properties they are renting out. Details about renters would need to be recorded so an entity Renters is required.
3.1.7 Summary
This section lists sum of the entities and assumptions made during the analysis of the specification. The next section aims to put these details together into a conceptual design. The first being the conceptual design.
3.2 Conceptual Design/Schema
This section attempts to describe the high abstract details of the database, independent of the particular database system which is going to be implemented. It will describe the information content of the database not the storage structures which are required to manage the information. The following will be discussed:
3.2.1 Attributes
Attributes discovered during the data analysis stage and general knowledge of the problem are placed into a data dictionary table which is shown in figure 3.4.
3.2.2 Initial Relations
The semantics of relation attributes are described here. The attributes are abbreviated and its definition is described in figure 3.3. These were the initial schemas before normalization was done on the relations. It includes the primary (underlined) and foreign key (specified by (fk) symbol) definitions.
BRANCH (BCH_NO, BCH_NAME, BCH_STREET, BCH_CITY, BCH_PCODE, BCH_TEL, BCH_TOTAL)
EMPLOYEE (EMP_NO, EMP_NAME, EMP_HDATE, EMP_JOB, EMP_SAL, EMP_MAN, EMP_SUP, EMP_SEC, GRP_NO(fk), BCH_NO(fk), PRP_NO(fk))
GROUP (GRP_NO, GRP_NAME, BCH_NO(fk))
MANAGER (EMP_NO, MNG_CARALLW, MNG_BONUS)
PROPERTY (PRP_NO, PRP_STREET, PRP_CITY, PRP_PCODE, PRP_TEL, PRP_VALUE, PRP_NADATE, PRP_DATE)
RENTER (RNT_NO, RNT_NAME, RNT_STREET, RNT_CITY, RNT_PCODE, RNT_TEL, FNT_FAX, RNT_SDATE, RNT_ENDDATE, RNT_PRICE, PRP_NO(fk))
OWNER (OWN_NO, OWN_NAME, OWN_STREET, OWN_CITY, OWN_PCODE, OWN_TEL, OWN_FAX, OWN_PRICE, PRP_NO(fk))
From these schemas we can see already there are a lot of redundancies and other anomalies which have to be ironed out. The next section describes the normalization process the relations have gone through to produce new relations and attributes.
3.2.3 Normalized relations
For each relation discovered in the previous section we will attempt to normalize in order to derive relational structures that avoid update anomalies in insertion, deletion, modification and access. Relations may already be at a certain level of normalization and it may not be necessary to do all levels of normalization. The three normal forms we used are described below [Ref. ?]:
First Normal Form (1NF): States that the domains of attributes must include only atomic (simple, indivisible) values and that the value of any attribute in a tuple must be a single value from the domain of that attribute. It is use to prevent multivalues attributes and composite attributes or in other words disallows having a set of values, a tuple of values, or a combination of both as an attribute value for a single tuple.
Second Normal Form (2NF): States that every non-key attribute must be fully dependent on the entire primary key (as there may be more than one primary key). The relation has to have full functional dependency.
Third Normal Form (3NF): States that every non-key attributes are mutually independent. You need to identify functional dependencies between non-key attributes and rewrite the relations so that each non key-attributes are functionally independent from each other.
Branch Relation
The branch entity does not need any normalization.
Employee Relation
The EMP_NAME is a composite attribute which could be broken down into first and last name to fulfill the 1NF rule but, it was decided that it was not necessary. Employees can deal with more than one property this can cause redundancy for every set of tuples in the relation as for every property an employee deals with will have the employee details repeated and with just a different property number. Therefore this can be decomposed into another relation called manages which contain the attributes PRP_NO and EMP_NO. See below for the normalized relation.
EMPLOYEE (EMP_NO, EMP_NAME, EMP_HDATE, EMP_JOB, EMP_MAN, EMP_SUP, EMP_SEC, GRP_NO(fk), BCH_NO(fk))
MANAGES (EMP_NO(fk), PRP_NO(fk))
Group Relation
The group relation does not need any normalization.
Property Relation
The property relation does not need any normalization
Renter Relation
The RNT_NAME is a composite attribute which could be broken down into first and last name to fulfill the 1NF rule but, it was decided that it was not necessary. Renter can rent only one property therefore there should not be any redundancy. However it was decided to create an entity called RENTS. This was because it was noticed that the RNT_SDATE, RNT_ENDDATE and RNT_PRICE depend on the property the renter was renting and not the renter hence not dependent on the primary key RNT_NO but the foreign key PRP_NO. Therefore the new relations are shown below.
RENTER (RNT_NO, RNT_NAME, RNT_STREET, RNT_CITY, RNT_PCODE, RNT_TEL, RNT_FAX, PRP_NO(fk))
RENTS (RNT_NO(fk), PRP_NO(fk), RNT_SDATE, RNT_ENDDATE, RNT_PRICE)
Owner Relation
The OWN_NAME is a composite attribute which could be broken down into first and last name to fulfill the 1NF rule but, it was decided that it was not necessary. Owners can own more than one property this can cause redundancy for every set of tuples in the relation, as for every property an owner owns will have the owner details repeated, with just a different property number. Therefore this can be decomposed into another relation called OWNS. Also what was noticed is that the OWN_PRICE & OWN_DATE depend on the property the owner was giving to the company to rent out hence not dependent on the primary key OWN_NO but the foreign key PRP_NO. Therefore the new relations are shown below.
OWNER (OWN_NO, OWN_NAME, OWN_STREET, OWN_CITY, OWN_PCODE, OWN_TEL, OWN_FAX)
OWNS (OWN_NO(fk), PRP_NO(fk), OWN_PRICE, OWN_DATE)
3.2.4 Entity Relationship Map
From the data analysis section we can produce an ER map which will describe the basic relationships, entities and constraints discovered. The ER map is shown in figure 3.1 without the attributes and in figure 3.2 with the attributes.
Figure 3.2 uses the same key in figure 3.1 and that described below.
Key (for figure 3.2 )
3.3 Data Dictionary
Below is the data dictionary for the database design we are going to use. It contains data such as whether it its a key, is it indexed, what are its constraints and so on. It is shown in figure 3.3 below.
| Table | Attribute Name | Attribute Abbreviation | Attribute Type | Domain Constraints | Primary Key | Foreign Key | Indexed |
| Branch | Branch Number | BCH_NO | Long | (1 , * ) | Yes | No | Yes |
| Branch Name | BCH_NAME | String | (1 , 50) | No | No | No | |
| Branch Street | BCH_STREET | String | (1 , 250) | No | No | No | |
| Branch City | BCH_CITY | String | (1 , 50) | No | No | No | |
| Branch Post Code | BCH_PCODE | String | (1 , 10) | No | No | No | |
| Branch Telephone | BCH_TEL | String | (1 , 20) | No | No | No | |
| Branch Fax | BCH_FAX | String | (1, 20) | No | No | No | |
| Branch Staff Total | BCH_STOTAL | Integer | (1 , *) | No | No | No | |
| Employee | Employee Number | EMP_NO | Long | (1 , *) | Yes | No | Yes |
| Employee Name | EMP_NAME | String | (1 , 50) | No | No | No | |
| Employee Job | EMP_JOB | String | (1 , 50) | No | No | No | |
| Employee Salary | EMP_SAL | Integer | (1 , *) | No | No | No | |
| Employee Manager | EMP_MAN | Long | (1 , *) | No | No | No | |
| Employee Supervisor | EMP_SUP | Long | (1 , *) | No | No | No | |
| Employee Secretary | EMP_SEC | Long | (1 , *) | No | No | No | |
| Group Number | GRP_NO | Long | (1 , *) | No | No | No | |
| Employee Hire Date | EMP_HDATE | Date | (Day , Month , Year) | No | No | No | |
| Branch Number | BCH_NO | Long | (1 , *) | No | Yes | Yes | |
| Group | Group Number | GRP_NO | Long | (1 , *) | Yes | No | Yes |
| Group Name | GRP_NAME | String | (1 , 50) | No | No | No | |
| Branch Number | BCH_NO | Long | (1 , *) | No | Yes | Yes | |
| Manager | Employee Number | EMP_NO | Long | (1 , *) | Yes | No | Yes |
| Manager Car Allowance | MNG_CARALLW | Integer | (1 , *) | No | No | No | |
| Manager Monthly Bonus | MNG_MBONUS | Integer | (1 , *) | No | No | No | |
| Manages | Employee Number | EMP_NO | Long | (1 , *) | No | Yes | Yes |
| Property Number | PRP_NO | Long | (1 , *) | No | Yes | Yes |
Figure 3.3
Table showing the data dictionary of the database design
| Table | Attribute Name | Attribute Abbreviation | Attribute Type | Domain Constraints | Primary Key | Foreign Key | Indexed |
| Property | Property Number | PRP_NO | Long | (1 , *) | Yes | No | Yes |
| Property Street | PRP_STREET | String | (1 , 250) | No | No | No | |
| Property City | PRP_CITY | String | (1 , 50) | No | No | No | |
| Property Post Code | PRP_PCODE | String | (1 , 10) | No | No | No | |
| Property Telephone | PRP_TEL | String | (1 , 20) | No | No | No | |
| Property Type | PRP_TYPE | String | (F , H) | No | No | No | |
| Property Value | PRP_VALUE | Long | (1 , *) | No | No | No | |
| Property Not Available Date | PRP_NADATE | Date | (Day , Month , Year) | No | No | No | |
| Renter | Renter Number | RNT_NO | Long | (1 , *) | Yes | No | Yes |
| Renter Name | RNT_NAME | String | (1 , 50) | No | No | No | |
| Renter Street | RNT_STREET | String | (1 , 250) | No | No | No | |
| Renter City | RNT_CITY | String | (1 , 50) | No | No | No | |
| Renter Post Code | RNT_PCODE | String | (1 , 10) | No | No | No | |
| Renter Telephone | RNT_TEL | String | (1 , 20) | No | No | No | |
| Renter Fax | RNT_FAX | String | (1 , 20) | No | No | No | |
| Rents | Renter Number | RNT_NO | Long | (1 , *) | No | Yes | Yes |
| Property Number | PRP_NO | Long | (1 , *) | No | Yes | Yes | |
| Rent Start Date | RNTS_SDATE | Date | (Day , Month , Year) | No | No | No | |
| Rent End Date | RNTS_EDATE | Date | (Day , Month , Year) | No | No | No | |
| Rent Price | RNTS_PRICE | Integer | (1 , *) | No | No | No | |
| Owner | Owner Number | OWN_NO | Long | (1 , *) | Yes | No | No |
| Owner Name | OWN_NAME | String | (1 , 50) | No | No | No | |
| Owner Street | OWN_STREET | String | (1 , 250) | No | No | No | |
| Owner City | OWN_CITY | String | (1 , 50) | No | No | No | |
| Owner Post Code | OWN_PCODE | String | (1 , 10) | No | No | No | |
| Owner Telephone | OWN_TEL | String | (1 , 20) | No | No | No | |
| Owner Fax | OWN_FAX | String | (1 , 20) | No | No | No | |
| Owns | Owner Number | OWN_NO | Long | (1 , *) | No | Yes | Yes |
| Property Number | PRP_NO | Long | (1 , *) | No | Yes | Yes | |
| Property Date | PRP_DATE | Date | (Day, Month, Year) | No | No | No | |
| Owner Price | OWN_PRICE | Integer | (1, *) | No | No | No |
Figure 3.3 (Cont.)
Key for figure 3.3
* Value limited by the type defined for the attribute
3.4 Transactions
This section briefly discusses some of the more likely transactions that are to occur in the DreamHome company. Examples of transactions that should be allowed are:
Transactions may result in accessing data from one site i.e. in centralized database design or several sites as in distributed design therefore each site will have a local transaction manager.
3.5 Summary
We have tried to show how we have analyzed each data that might be required to make the operation of your company smoother. The conceptual design is the basis for all the 3 designs we shall be discussing. Any changes in the data must be made in the conceptual design and then change all the logical and physical design of each of the 3 database systems.
4 Centralized Relational Database Management System
From the conceptual design we now come to specifics of logical and physical design based on the particular database design. First the class of DBMS is used here. It is a relational database design and the logical design will be based upon this. The logical design phase will set the relational table structures, indexes and views. Figure 4.1 below shows how the centralized database system will be stored. The database server will be in London from which Glasgow and Cardiff will be able to access data from through the WAN.
Figure 4.1
Centralized Database Structure of DreamHome
4.1 Logical design
The logical design types are defined either as characters e.g. CHAR (number of characters), numbers e.g. NUMBER(digits, precision). DATE specifies a date given as Day/Month/Year. BOOLEAN requires a 1 or 0 to specify Yes or No. NOT NULL indicates that a value must be specified for that attribute. UNIQUE specifies that the attribute must be unique i.e. all other values in that field must be different. Primary keys are defined as PRIMARY KEY. Relationships are defined by REFERENCES. UPDATE CASCADE and DELETE CASCADE causes data from one table and related data from other tables to be updated or deleted during a transaction.
4.1.1 Tables
Table name: BRANCH
CREATE TABLE BRANCH
(
BCH_NO NUMBER(2) NOT NULL, UNIQUE,
BCH_NAME CHAR(50) NOT NULL,
BCH_STREET CHAR(250) NOT NULL,
BCH_CITY CHAR(50) NOT NULL,
BCH_PCODE CHAR(10) NOT NULL,
BCH_TEL CHAR(20) NOT NULL,
BCH_FAX CHAR(20)
BCH_STOTAL NUMBER(5)
PRIMARY KEY (BCH_NO)
);
Table name: EMPLOYEE
CREATE TABLE EMPLOYEE
(
EMP_NO NUMBER(8) NOT NULL, UNIQUE
EMP_NAME CHAR(50) NOT NULL, UNIQUE
EMP_JOB CHAR(30) NOT NULL
EMP_SAL NUMBER(6)
EMP_HDATE DATE NOT NULL
EMP_MAN NUMBER(8)
EMP_SUP NUMBER(8)
EMP_SEC NUMBER(8)
BCH_NO NUMBER(8) NOT NULL
GRP_NO NUMBER(8)
PRIMARY KEY (EMP_NO),
FOREIGN KEY (BCH_NO) REFERENCES BRANCH
ON DELETE CASCADE
ON UPDATE CASCADE,
FOREIGN KEY (GRP_NO) REFERENCES GROUP
ON DELETE CASCADE
ON UPDATE CASCADE
);
Table name: GROUP
CREATE TABLE GROUP
(
GRP_NO NUMBER(8) NOT NULL, UNIQUE,
GRP_NAME CHAR(50) NOT NULL, UNIQUE,
BCH_NO NUMBER(8) NOT NULL,
PRIMARY KEY (GRP_NO),
FOREIGN KEY (BCH_NO) REFERENCES BRANCH
ON DELETE CASCADE
ON UPDATE CASCADE,
);
Table name: MANAGES
CREATE TABLE MANAGES
(
EMP_NO NUMBER(8) NOT NULL,
PRP_NO NUMBER(8) NOT NULL,
FOREIGN KEY (EMP_NO) REFERENCES EMPLOYEE
ON DELETE CASCADE
ON UPDATE CASCADE,
FOREIGN KEY (PRP_NO) REFERENCES PROPERTY
ON DELETE CASCADE
ON UPDATE CASCADE
);
Table name: MANAGER
CREATE TABLE MANAGER
(
EMP_NO NUMBER(8) NOT NULL, UNIQUE,
MNG_CARALLW NUMBER(6)
MNG_MBONUS NUMBER(6,2)
FOREIGN KEY (EMP_NO) REFERENCES EMPLOYEE
ON DELETE CASCADE
ON UPDATE CASCADE
);
Table name: PROPERTY
CREATE TABLE PROPERTY
(
PRP_NO NUMBER(8) NOT NULL, UNIQUE,
PRP_STREET CHAR(250) NOT NULL
PRP_CITY CHAR(50) NOT NULL
PRP_PCODE CHAR(10) NOT NULL
PRP_TEL CHAR(20) NOT NULL
PRP_TYPE (F, H) NOT NULL
PRP_VALUE NUMBER(7) NOT NULL
PRP_NADATE DATE
PRIMARY KEY (PRP_NO)
)
Table name: OWNER
CREATE TABLE OWNER
(
OWN_NO NUMBER(8) NOT NULL, UNIQUE,
OWN_NAME CHAR(50) NOT NULL, UNIQUE,
OWN STREET CHAR(250) NOT NULL
OWN_CITY CHAR(50) NOT NULL
OWN_PCODE CHAR(10) NOT NULL
OWN_TEL CHAR(20) NOT NULL
OWN_FAX CHAR(20) NOT NULL
PRIMARY KEY (OWN_NO)
);
Table name: OWNS
CREATE TABLE OWNS
(
OWN_NO NUMBER(8) NOT NULL
OWN_PRICE NUMBER(4) NOT NULL
PRP_NO NUMBER(8) NOT NULL
PRP_DATE DATE NOT NULL
FOREIGN KEY (OWN_NO) REFERENCES OWNER
ON DELETE CASCADE
ON UPDATE CASCADE,
FOREIGN KEY (PRP_NO) REFERENCES PROPERTY
ON DELETE CASCADE
ON UPDATE CASCADE
);
Table name: RENTER
CREATE TABLE RENTER
(
RNT_NO NUMBER(8) NOT NULL, UNIQUE,
RNT_NAME CHAR(50) NOT NULL, UNIQUE,
RNT_STREET CHAR(250) NOT NULL
RNT_CITY CHAR(50) NOT NULL
RNT_PCODE CHAR(10) NOT NULL
RNT_TEL CHAR(20) NOT NULL
RNT_FAX CHAR(20) NOT NULL
PRIMARY KEY (RNT_NO)
);
Table name: RENTS
CREATE TABLE RENTS
(
RNT_NO NUMBER(8) NOT NULL
PRP_NO NUMBER(8) NOT NULL
RNTS_SDATE DATE NOT NULL
RNTS_EDATE DATE
RNTS_PRICE NUMBER(4) NOT NULL
FOREIGN KEY (RNT_NO) REFERENCES RENTER
ON DELETE CASCADE
ON UPDATE CASCADE,
FOREIGN KEY (PRP_NO) REFERENCES PROPERTY
ON DELETE CASCADE
ON UPDATE CASCADE
);
4.1.2 Indexes
Index are used to improve the speed used on foreign keys as these link the relationships and are the most often used keys in querying. Primary keys already have indexes so definition for foreign keys indexes are defined here.
Table name: EMPLOYEE
CREATE INDEX EMP_BCH_NO
ON EMPLOYEE(BCH_NO);
CREATE INDEX EMP_GRP_NO
ON EMPLOYEE(GRP_NO);
Table name: GROUP
CREATE INDEX GRP_BCH_NO
ON GROUP(BCH_NO);
Table name: MANAGER
CREATE UNIQUE INDEX MNG_EMP_NO
ON MANAGER(EMP_NO);
Table name: MANAGES
CREATE INDEX MNGS_PRP_NO
ON MANAGES(PRP_NO);
CREATE INDEX MNGS_EMP_NO
ON MANAGES(EMP_NO);
Table name: OWNS
CREATE INDEX OWNS_OWN_NO
ON OWNER(OWN_NO);
CREATE INDEX OWNS_PRP_NO
ON OWNER(PRP_NO);
Table name RENTS
CREATE UNIQUE INDEX RNTS_RNT_NO
ON RENTS(RNT_NO);
CREATE UNIQUE INDEX RNTS_PRP_NO
ON RENTS(PRP_NO);
4.1.3 Queries and Transactions
Below is some of the queries which enable staff to view certain sets of data. Here is some examples of queries listed below.
Some SQL’s to find out queries above is shown below.
Example on query 4...
SELECT SUM(BRANCH.BCH_STOTAL)
FROM BRANCH
Example on query 7...
Belonging to the branch London with branch number 1.
SELECT * FROM EMPLOYEE E
WHERE E.BCH_NO = 1
AND E.EMP_JOB = ‘Supervisor’
ORDER BY E.EMP_NAME;
Example on query 11...
Select the property a renter is renting given the renter name is ‘Bill’
SELECT * FROM PROPERTY P, RENTS RS, RENTER R
WHERE R.RNT_NAME = ‘Bill’
AND RS.RNT_NO = R.RNT_NO
AND RS.PRP_NO = P.PRP_NO;
Example on query 21...
This will provide data about the properties and owners from Glasgow.
SELECT * FROM PROPERTY P, OWNER O, OWNS OS
WHERE P.CITY = ‘Glasgow’
AND P.NAVAIL != NULL
AND P.PRP_NO = OS.PRP_NO
AND OS.OWN_NO = O.OWN_NO
ORDER BY P.PRP_NO;
Below is a list some transactions for your company that we will use. It is divided into two section. One is views/queries where views allows you to restricted certain data to particular users and Transactions which will allow the user e.g. the manager or administrator of the database to insert, delete or edit the data in the database.
Inserts
Example for inserting employee details...
INSERT INTO EMPLOYEE
VALUES (209, ‘Robert Pancic’, ‘Supervisor’, �15000, 45, 56, 73, 2, ‘12/12/1997’, 1)
Values are entered based on the order given in the data dictionary in section 3.
Updates
DreamHome will be allowed to update any particular data in any entity as long as there is no referential integrity problems such as constraints on entering data.
Deletes
Deleting can causes data to be deleted in different table. For example, if a property has been withdrawn but and details kept for 3 years you can delete those properties. If an owner owns all the properties that is to be deleted than the owner details with be deleted as well. This is due to the cascade delete option described in the tables structure in section 4.1.1.
Example on deleting an owner with a given name ‘Bill’...
DELETE FROM OWNER O
WHERE O.OWN_NAME = ‘Bill’
4.1.4 Constraints on entering data
4.1.5 Constraints as assertions or triggers
The DreamHome company has specified 2 explicit constraints for the system which do not fall in the categories of keys, entity integrity and referential integrity constraints. Below are the designs structures which will be used as a guide to implementing these constraints. There are other ways of achieving these constraints but, we have chose the trigger method described [Ref. 1].
First Constraint
There are a minimum of 5 and a maximum of 10 employees per group. Therefore any new employee must belong to a group. But, cannot join a group already containing 10 employees and a group cannot fall below 5 employees. To represent this the data from figure 3.3 was used.
PARAMETERS EMP_VAL
CREATE ASSERTION GROUP_CONSTRAINT
CHECK (EXISTS (SELECT COUNT(*) FROM EMPLOYEE E, GROUP G
WHERE E.GRP_NO=G.GRP_NO
AND COUNT (*) BETWEEN 5 AND 10
AND E.EMP_NO=EMP_VAL));
This will return false if the constraint is violated. The constraint is satisfied by a database state if no combination of tuples in the database state violates the constraint. Thereby informing you the manager or administrator responsible for managing employees if this restriction has been broken.
PARAMETERS EMP_VAL
DEFINE TRIGGER GROUP_CONSTRAINT ON EMPLOYEE E, GROUP G:
COUNT(*)
AND E.GRP_NO=G.GRP_NO
AND COUNT (*) NOT BETWEEN 5 AND 10
AND E.EMP_NO=EMP_VAL
ACTION_PROCEDURE INFORM_MANAGER(MNG_NO);
Where EMP_VAL is the value of the employee to add to the group or delete from the group. Taken from the EMP_NO in the EMPLOYEE table.
Second Constraint
Each employee can deal with up to 20 properties at any one time. Therefore if a employee starts being allocated a 21st property to deal with this will be determined by the trigger. To represent this the data from figure 3.3 was used.
PARAMETERS EMP_VAL
CREATE ASSERTION PROPERTY_CONSTRAINT
CHECK (EXISTS (SELECT COUNT(*) FROM EMPLOYEE E, MANAGES M
WHERE E.PRP_NO=M.PRP_NO
AND COUNT (*) BETWEEN 0 AND 20
AND E.EMP_NO=EMP_VAL));
This will return false if the constraint is violated. The constraint is satisfied by a database state if no combination of tuples in the database state violates the constraint. Thereby informing you the manager or administrator responsible for managing employees if this restriction has been broken.
PARAMETERS EMP_VAL
DEFINE TRIGGER GROUP_CONSTRAINT ON EMPLOYEE E, MANAGES M:
COUNT(*)
AND E.PRP_NO=M.PRP_NO
AND COUNT (*) NOT BETWEEN 0 AND 20
AND E.EMP_NO=EMP_VAL
ACTION_PROCEDURE INFORM_MANAGER(MNG_NO);
Where EMP_VAL is the value of the employee to check if he/she has more than 20 properties. Taken from the EMP_NO in the EMPLOYEE table.
One disadvantage of using these form of designs is that there can be an overhead of testing these arbitrary assertions. But, processing in databases have increased dramatically and it should not be much of a factor. If during the testing of the design it is discovered that assertions/triggers slow has insufficient implementation time factor then another method will be used.
4.2 Physical Design
The physical design involves determining the internal storage structures and access paths for the database. These involve types of indexing, clustering of related records, linking related records via pointers and various type of hashing. Here as well as in the other designs we will have to take into consideration [Ref. 1]:
For the centralized database system this database will be stored in a one place at the London site. Without actual implementation of the particular database design it is not simple to determine factors that are slowing things such as time constraints on executions of queries so that more refined optimization can occur. Our initial suggestion for the centralized DBMS is as follows.
We have used attributes which are primarily required for selecting records and foreign keys to be indexed as well. As the file size increases for storing data so will the index. Indexes are required so that faster access can be provided to the users of the system for retrieving records. We have taken into account increases in records structure by providing hardware to accommodate this. We would suggest as for all other designs to add a monitoring utility to collect performance statistic which will be kept in the system, catalog or data dictionary for analysis. Example of data stored would be, I/O activity on files. frequency of index usage. Our queries specified before makes extensive use of the indexes and keys.
All fields in the database can be updated or deleted except key candidates proposed as an access structure i.e. all the keys in the tables. The files will be stored unordered in the CDBMS to enable faster updating, insertion and deletion of the data as if the data is stored in an order the new data would have to be placed in the correct position. This will enable transactions to be supported more efficiently.
Next are a few advantages and disadvantages of having a RDBMS [Ref. 9].
4.3 Advantages
Relational data structure can be hidden away from users and designers therefore the model is structurally independence and data independence. The relational model is the dominant model in the current world and is very powerful with a flexible query capability. We can concentrate more on the logical side of the database rather than the physical side since the RDBMS performs the unseen hardware tasks.
4.4 Disadvantages
Requires more hardware and operation overhead, and is usually slower than other database systems. Also another disadvantage is that it cannot do real world objects.
4.5 Summary
This is the RDBMS design. The next section describes the DDBMS design which is similar to this design except that the data is distributed.
5 Centralized Relational Distributed Database System
The DDBMS is essentially the same as the RDBMS design but the main difference is that the data is stored in separate locations throughout the three sites in the country i.e. London, Cardiff and Glasgow sites. This section will describe the data fragmentation and transparency for the DreamHome company design. Considering the company having three sites at London (site 1), Glasgow (site 2) and Cardiff (site 3).
5.1 Revised design
The data from the ER will be broken up into different components as shown in figure 5.1 below and is used as a guide for data fragmentation for this design.
| Table | London | Cardiff | Glasgow | Fragmentation Type |
| BRANCH | LCG | LCG | LCG | CR |
| MANAGER | LCG | LCG | LCG | CR |
| EMPLOYEE | LCG | C | G | SR |
| GROUP | LCG | C | G | SR |
| MANAGES | LCG | LCG | LCG | CR |
| PROPERTY | L | C | G | P |
| OWNER | L | C | G | P |
| OWNS | L | C | G | P |
| RENTER | L | C | G | P |
| RENTS | L | C | G | P |
Figure 5.1
Table showing the horizontal fragmentation of the data over the three branches
Each branch is connected to the LAN/WAN network in order for them to communicate with each other. This is shown in figure 5.2 below.
Figure 5.2
Distributed database structure of DreamHome
Each branch site will have its own computer system to store the database. Each site will communicate with others via a communications network and access data stored at another branch office.
5.2 Data Fragmentation
Data fragmentation is shown by providing you with some examples of how this will be achieved. We start by analyzing the relation PROPERTY(PRP_NO, PRP_STREET, PRP_CITY, PRP_PCODE, PRP_TEL, PRP_TYPE PRP_VALUE, PRP_NADATE). PRP_CITY assumes just three values, "London", "Glasgow" and "Cardiff". Let us assume that there is just one important application requiring all attributes of properties with a given number PRP_NO as $X. A SQL query for this application is:
SELECT *
FROM PROPERTY
WHERE PRP_NO = $X
This application is issued at any one of the sites: if it is issued at site 1, it references PROPERTY whose PRP_CITY is "London" with 80 percent probability, PRP_CITY is "Glasgow" with 10 percent probability, PRP_CITY is "Cardiff" with 10 percent probability; if it is issued at site 2, it references PROPERTY whose PRP_CITY is "London" with 10 percent probability, PRP_CITY is "Glasgow" with 80 percent probability, PRP_CITY is "Cardiff" with 10 percent probability; if it is issued at site 2, it references PROPERTY whose PRP_CITY is "London" with 10 percent probability, PRP_CITY is "Glasgow" with 10 percent probability, PRP_CITY is "Cardiff" with 80 percent probability. This comes from the fact that branches in one city tend to handle with properties which are close to them.
We can apply to this simple case the method for producing the predicates:
Since the set {p1, p2, p3}is complete and minimal, the search is terminated.
Though simple, this example shows two important features:
m1: p1 ^ p2
m2: p1 ^ � p2
m3: p1 ^ p3
m4: p1 ^ � p3
m5: p2 ^ p3
m6: p2 ^ � p3
but we know that: p1 => � p2 and p1 => � p3 and p2 => � p3, and there fore we can infer the m1, m3 and m5 are contradictions, m2, m4 and m6 reduce to the three predicates p1, p2 and p3.
Suppose company locations in each city (London, Glasgow and Cardiff) require only data regarding local properties. Based on such requirements, we decide to distribute the data by PRP_CITY. Therefore, we define the horizontal partitions to conform to the structure shown in figure 5.3 which shows part of the full tuple. Figures 5.4 and 5.5 (a-c) shows the rest of the horizontal fragmentation.
PRP_NO |
PRP_STREET |
PRP_CITY |
PRP_PCODE |
PRP_TEL |
PRP_TYPE |
11 |
#12 Bert Rd. |
London |
SE10 7C |
0171 4699111 |
flat |
12 |
#15 High St. |
Glasgow |
SW8 23 |
5685892 |
flat |
13 |
#8 Church St. |
London |
E15 65 |
0181 6852387 |
house |
14 |
#28 Down Rd. |
Cardiff |
W9 35 |
8653227 |
flat |
15 |
#19 Cedar Rd. |
Cardiff |
NW1 1A |
3533855 |
house |
Figure 5.3
Table showing a sample PROPERTY table
FRAGMENT NAME |
LOCATION |
CONDITION |
NODE NAME |
PROPERTY NUMBERS |
NUMBER OF TUPLES |
P1 |
London | PRP_CITY = "London" | London | 11, 13 |
2 |
P2 |
Glasgow | PRP_CITY = "Glasgow" | Glasgow | 12 |
1 |
P3 |
Cardiff | PRP_CITY = "Cardiff" | Cardiff | 14, 15 |
2 |
Figure 5.4
Table showing the horizontal fragmentation of the PROPERTY table by PRP_CITY
P1
PRP_NO |
PRP_STREET |
PRP_CITY |
PRP_PCODE |
PRP_TEL |
PRP_TYPE |
11 |
#12 Bert Rd. |
London |
SE10 7C |
4699111 |
flat |
13 |
#8 Church St. |
London |
E15 65 |
6852387 |
house |
P2
PRP_NO |
PRP_STREET |
PRP_CITY |
PRP_PCODE |
PRP_TEL |
PRP_TYPE |
12 |
#15 High St. |
Glasgow |
SW8 23 |
5685892 |
flat |
P3
PRP_NO |
PRP_STREET |
PRP_CITY |
PRP_PCODE |
PRP_TEL |
PRP_TYPE |
14 |
#28 Down Rd. |
Cardiff |
W9 35 |
8653227 |
flat |
15 |
#19 Cedar Rd. |
Cardiff |
NW1 1A |
3533855 |
house |
Figures 5.5(a-c)
Tables showing horizontal fragmentation of the PROPERTY table
Horizontal fragmentation PROPERTY:
P1 = s PRP_CITY = ’London’(PROPERTY)
P2 = s PRP_CITY = ’Glasgow’(PROPERTY)
P3 = s PRP_CITY = ’Cardiff’(PROPERTY)
This fragmentation schema satisfy the correctness rules:
We can design fragmentation for other tables at the same way. Figure 5.6 shows horizontal fragmentation of the RENTER. Figure 5.7 shows horizontal fragmentation of the OWNER. Figure 5.8 shows horizontal fragmentation of the EMPLOYEE.
Horizontal fragmentation RENTER:
R1 = s RNT_CITY = ’London’(RENTER)
R2 = s RNT _CITY = ’Glasgow’(RENTER)
R3 = s RNT _CITY = ’Cardiff’(RENTER)
Horizontal fragmentation OWNER:
O1 = s OWN_CITY = ’London’(OWNER)
O2 = s OWN _CITY = ’Glasgow’(OWNER)
O3 = s OWN _CITY = ’Cardiff’(OWNER)
Horizontal fragmentation EMPLOYEE:
E1 = s BCH_NO = ’DH1’(EMPLOYEE)
E2 = s BCH_NO = ’DH2’(EMPLOYEE)
E3 = s BCH_NO = ’DH3’(EMPLOYEE)
FRAGMENT NAME |
LOCATION |
CONDITION |
NODE NAME |
R1 |
London | RNT_CITY = "London" | London |
R2 |
Glasgow | RNT_CITY = "Glasgow" | Glasgow |
R3 |
Cardiff | RNT_CITY = "Cardiff" | Cardiff |
Figure 5.6
Table showing horizontal fragmentation of the RENTER table by RNT_CITY
FRAGMENT NAME |
LOCATION |
CONDITION |
NODE NAME |
O1 |
London | OWN_CITY = "London" | London |
O2 |
Glasgow | OWN_CITY = "Glasgow" | Glasgow |
O3 |
Cardiff | OWN_CITY = "Cardiff" | Cardiff |
Figure 5.7
Table showing horizontal fragmentation of the OWNER table by OWN_CITY
FRAGMENT NAME |
LOCATION |
CONDITION |
NODE NAME |
E1 |
London | BCH_NO = "DH1" | DH1 |
E2 |
Glasgow | BCH_NO = "DH2" | DH2 |
E3 |
Cardiff | BCH_NO = "DH3" | DH3 |
Figure 5.8
Table showing horizontal fragmentation of the EMPLOYEE table by BCH_NO
5.3 Data Replication
A fully replicated database tends to be impractical due to the amount of overhead that it will impose on the system. A partially replicated database stores multiple copies of some database fragments at multiple sites. Most DBMSs are able to handle the partially replicated database well. Two factors influence the decision to use data replication: database size, usage frequency.
We assume that the branch at London site is important in DreamHome. People working there want to know information of the whole employee frequently. To reduce overhead communication, we need a replicate EMPLOYEE in London branch.
5.4 Data Allocation
Data allocation describes the process of deciding where to locate data. Data distribution over a computer network is achieved through data partition and data replication. See figure 9. BRANCH and MANAGER are very small size table and operations on them are few. We do not need to fragment them and store them at all branches. EMPLOYEE will be stored at London branch, while Glasgow stores E2, Cardiff stores E3. For GROUP we will design data allocation the same as EMPLOYEE. For the other tables we use partition to let each site store its fragmentation.
ENTITY |
London |
Glasgow |
Cardiff |
| BRANCH | BRANCH |
BRANCH |
BRANCH |
| MANAGER | MANAGER |
MANAGER |
MANAGER |
| GROUP | G1,G2,G3 |
G2 |
G3 |
| EMPLOYEE | E1,E2,E3 |
E2 |
E3 |
| MANAGES | M1 |
M2 |
M3 |
| PROPERTY | P1 |
P2 |
P3 |
| RENTER | R1 |
R2 |
R3 |
| RENTS | RE1 |
RE2 |
RE3 |
| OWNER | O1 |
O2 |
O3 |
| OWNS | OW1 |
OW2 |
OW3 |
Figure 5.9
Table showing the data allocation for the DreamHome database
5.5 Data Transparency
This distributed database system supports a set of transparency features which have the common property of making the end user think that he or she is working with a centralized DBMS; all the complexities of a distributed database are hidden or transparent to the user.
5.5.1 Distribution transparency
Allows a distributed database to be treated as a single logical database. The database supports fragmentation transparency: The query conforms to a non-distributed database query format. It does not specify fragment names or locations. The query thus reads:
SELECT *
FROM PROPERTY
WHERE TYPE = "F"
5.5.2 Transaction transparency
Allows a transaction to update data at several network sites.
5.5.3 Failure transparency
Ensures that, even in the event of a node failure, the system will continue to operate.
5.5.4 Performance transparency
Allows the system to perform as if it were a centralized DBMS.
5.5.5 Heterogeneity transparency
Allows the integration of several different local DBMSs (relational, network, and Hierarchical) under a common or global schema.
We will be suggesting the distributed design to you later in the report as well as here. Here are some of the following reasons to consider the distributed designs [Ref. 9].
5.6 Advantages
5.7 Disadvantages
6 Object Oriented Database System
Now to our final design about OODBMS which is similar to the RDBMS in its location and data stored but there are some difference which are now discussed. Object-Oriented database will relate your system to real world objects. You will be able to deal directly with real objects in a real world, instead of database functions. Security will be of high concern since this approach will hide you raw data from the public view; i.e. only authorised personnel will have the privilege to amend data.
6.1 Initial Problem Statement
After a series of interviews your company a problem statement was written and it is as follows:
"A system is required, the system will allow owners to rent out their property to renters, through one of DreamHome’s branch, an employee of DreamHome can handle up to 20 such properties, the properties are assigned to a particular branch these employee will belong to a group of not more than 5, the group will be headed by a supervisor, these groups will also have a secretary. Each branch will have one manager."
6.2 Object Identification
From entities identified in section 3 and the problem statement in section 6.1 the following objects were identified:
MANAGER EMPLOYEE BRANCH
GROUP RENTER PROPERTY
OWNER Manages Rents
Owns
6.3 Class Identification
After discarding the external objects and class relationships (for later use), we have the following objects:
OWNER BRANCH
PROPERTY EMPLOYEE
RENTER MANAGER
GROUP
6.4 Relationships Identification and Modeling
The table in figure 6.1 shows the relationships between the objects and their inverse relationships which makes it easy to query or to do transactions on the objects.
Objects |
Relationship |
Inverse |
Object |
manager |
manages |
is_managed_by |
employee |
employee |
work-in |
is_made_up_of |
branch |
owner |
owns |
is_owned_by |
property |
renter |
rents |
is_rented_by |
property |
employee |
belong-to |
has |
group |
employee |
handles |
is_handled_by |
property |
Figure 6.1
Table showing the normal and inverse relationships
6.5 Class Hierarchy
One of the advantages of using OODBMS is inheritance. This can be seen in figure 6.2. There are 8 objects of which 4 are human objects i.e. employee, owner, renter, manager. They have similar attributes and methods. For example, name, street and so on. Therefore a Person object was created to allow the human objects to inherit these functions as well as have those methods and attributes which are specific to themselves.
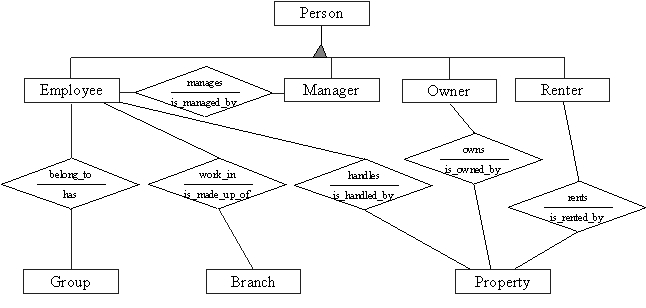
Figure 6.2
The class hierarchy diagram
6.6 Class Definition
The classes that are involved in the system are defined below in addition structures have also been defined.
struct name{
firstname: String;
lastname: String;
};
struct address{
street: string;
city: string;
postcode: string;
telephone: string;
fax: string;
};
class person{
ref name;
ref address;
dateofbirth: date;
};
class branch{
BCH_NO: long;
ref address:
BCH_NAME: string;
BCH_STOTAL: integer;
}
class employee is-a person{
EMP_NO: long;
EMP_JOB: string;
EMP_SAL: integer;
EMP_MAN: long;
EMP_SUP: long;
EMP_SEC: long;
GRP_NO: long;
EMP_HDATE: long;
BCH_NO: long;
};
class group{
GRP_NO: long;
GRP_NAME: string;
BCH_NO: long;
};
class manager is-an employee{
MNG_NO: long;
MNG_CARALLW: integer;
MNG_MBONUS: integer;
};
class property{
ref address:
PRP_NO: long;
PRP_VALUE: long;
PRP_NADATE: date;
};
class renter is a person{
RNT_NO: long;
ref address:
ref name;
};
class owner is-a person{
OWN_NO: long;
ref address:
ref name;
};
6.7 Schema Definition
The interfaces are defined in detail here width some methods suggested. There would be far more methods than those suggested. All interfaces will have methods such as get() and set() on all the attributes and objects.
interface Person {
//type property
supertype: Atomic_object;
extend Persons
//instance property
Struct <string: first_name, string:last_name> name;
Struct <street: string;
city: string;
postcode: string;
telephone: string;
fax: string> Address;
dateofbirth: DOB;
Gender: Enumeration {F,M};
//instance operation
Age();
}
interface Branch {
//type property
supertype: Atomic_object;
extend Branches;
BCH_NAME: String;
//instance property
Keys BCH_NO: long;
BCH_STOTAL: long;
is_made_up_of:Set<Employee>inverse Employee::work_in;
//instance operation
TotalStaffInBranch();
}
interface Employee {
//type property
supertype: Person;
extend Employees;
//instance property
Keys EMP_NO: long;
EMP_JOB: string;
EMP_SAL: integer;
EMP_MAN: long;
EMP_SUP: long;
EMP_SEC: long;
GRP_NO: long;
EMP_HDATE: date;
BCH_NO: long;
work_in:Set<Branch>inverse Branch::is_made_up_of;
is_managed_by:Manager inverse Manager::manages;
belong_to:Group inverse Group::has;
handles:Property inverse Property::is_handled_by;
//instance operation
AvgSalary();
MinSalary();
MaxSalary();
Job();
}
interface Group {
supertype: Employee;
extend Groups;
//instance property
Keys GRP_NO: long;
GRP_NAME: string;
BCH_NO: long;
has:Set<Employee>inverse Employee::belong_to;
//instance operation
GetGrpName();
EmpPerGroup();
}
The method EmpPerGroup(); fulfills the constraint that there should only be 5 to 10 employees in a group.
interface Manager {
//type property
supertype: Employee;
extend Managers;
//instance property
EMP_NO: long;
MNG_CARALLW: integer;
MNG_MBONUS: integer;
manages:Set<Employee>inverse Employee::is_managed_by;
//instance operation
ManagerBonus();
ManagerCarAllowance();
}
interface Property {
//type property
supertype Atomic_object;
extend Properties
ref address;
//instance property
Keys PRP_NO: long;
PRP_VALUE: long;
PRP_NADATE: date;
is_owned_by:Set<Owner>inverse Owner::owns;
is_rented_by:Renter inverse Renter::rents;
is_handled_by:Employee inverse Employee::handles;
//instance operation
AvgValue();
MinValue();
MaxValue();
PropPerEmployee();
TotalRentedForPeriod();
}
The method PropPerEmployee(); fulfills the constraint that there should only be up to 20 properties managed by an employee at any one time.
interface Renter{
//type property
supertype: Person;
extend Renters;
ref name;
ref address;
//instance property
Keys RNT_NO: long;
rents:Set<Property>inverse Property::is_rented_by;
//instance operation
GetRenter();
SetRenter();
PropertyRenting();
}
interface Owner {
//type property
supertype Person;
extend Owners;
ref name;
ref address;
//instance property
Keys OWN_NO: long;
owns:Set<Property>inverse Property::is_owned_by;
//instance operation
SetOwner();
GetOwner();
HowManyProperties();
}
The next section discusses some of the advantages and disadvantages of OODBMS design.
6.8 Advantages
6.9 Disadvantages
6.10 Summary
The concludes the three database designs. Now a discussion on other related topics which affect all three designs. These includes security and recovery and backup.
7 Security
Security measures will ensure that the data is stored safety in the database. especially in a multi-user database system which these designs are. This is to prevent someone entering inconsistency data deliberately. We would need your company policy to ensure we can assist in how the data is stored, accessed and managed within a data security and privacy framework. Access is limited through the use of access rights and access authorization.
This section describes the suggested security rights by us and is based on the conceptual schema in section 3.2. This can be subject to change depending on which system is to be implemented and when the system is put into practice, more changes may need to be made depending on your needs and requirements. Each table is discussed below with a brief justification of why.
7.1 Branch
| Type of User | Update | Insert | Delete | Administrator |
| Managers | Yes | Yes | Yes | Yes |
| Supervisors | No | No | No | No |
| Secretaries | No | No | No | No |
| Other | No | No | No | No |
Figure 7.1
Table showing the rights on the Branch table
Branch details are not concerned with any other type of employee apart from manager.
7.2 Manages
| Type of User | Update | Insert | Delete | Administrator |
| Managers | Yes | Yes | Yes | Yes |
| Supervisors | No | No | No | No |
| Secretaries | No | No | No | No |
| Other | No | No | No | No |
Figure 7.2
Table showing the rights on the Manages table
Stores the relationship between to tables EMPLOYEE and PROPERTY. This table is not concerned with any other type of employee apart from manager for administrative purposes.
7.3 Rents
| Type of User | Update | Insert | Delete | Administrator |
| Managers | Yes | Yes | Yes | Yes |
| Supervisors | No | No | No | No |
| Secretaries | No | No | No | No |
| Other | No | No | No | No |
Figure 7.3
Table showing the rights on the Rents table
Stores the relationship between two tables RENTER and PROPERT. This table is not concerned with any other type of employee apart from manager for administrative purposes.
7.4 Owns
| Type of User | Update | Insert | Delete | Administrator |
| Managers | Yes | Yes | Yes | Yes |
| Supervisors | No | No | No | No |
| Secretaries | No | No | No | No |
| Other | No | No | No | No |
Figure 7.4
Table showing the rights on the Owns table
Stores the relationship between two tables OWNER and PROPERTY. This table is not concerned with any other type of employee apart from manager for administrative purposes.
7.5 Manager
| Type of User | Update | Insert | Delete | Administrator |
| Managers | Yes | Yes | Yes | Yes |
| Supervisors | No | No | No | No |
| Secretaries | No | No | No | No |
| Other | No | No | No | No |
Figure 7.5
Table showing the rights on the Manager table
Only managers are concerned with their own data
7.6 Owner
| Type of User | Update | Insert | Delete | Administrator |
| Managers | Yes | Yes | Yes | Yes |
| Supervisors | Yes | No | Yes | No |
| Secretaries | Yes | No | No | No |
| Other | Yes | Yes | Yes | No |
Figure 7.6
Table showing the rights on the Owner table
Managers has all rights. Supervisors have update and delete rights, as the supervisor is supervising a group of staff so should be able to make changes or delete anything that is required but is not required to insert data as the supervisor does not deal with owners. Secretary has rights to update some data about owners such as if the wrong address was entered about a property but does not required to insert or delete any owners. The other employees have update, insert and delete on owners that they are concerned with.
7.7 Renter
| Type of User | Update | Insert | Delete | Administrator |
| Managers | Yes | Yes | Yes | Yes |
| Supervisors | Yes | No | Yes | No |
| Secretaries | Yes | No | No | No |
| Other | Yes | Yes | Yes | No |
Figure 7.7
Table showing the rights on the Renter table
Managers has all rights, Supervisors have update and delete rights as the supervisor is supervising a group of staff so should be able to make changes or delete anything that is required but is not required to insert data as the supervisor does not deal with renters. Secretary has rights to update some data about renters such as the wrong address was entered about a property but does not required top insert of delete any renters. The other employees have update, insert and delete on renters that they are concerned with.
7.8 Property
| Type of User | Update | Insert | Delete | Administrator |
| Managers | Yes | Yes | Yes | Yes |
| Supervisors | Yes | No | Yes | No |
| Secretaries | Yes | No | No | No |
| Other | Yes | Yes | Yes | No |
Figure 7.8
Table showing the rights on the Property table
Managers has all rights. Supervisors have update and delete rights as the supervisor is supervising a group of staff so should be able to make changes or delete anything that is required but is not required to insert data as the supervisor does not deal with properties. Secretary has rights to update some data about properties such as the wrong address was entered about a property but does not required top insert of delete any properties. The other employees have update, insert and delete on properties that they are concerned with.
7.9 Group
| Type of User | Update | Insert | Delete | Administrator |
| Managers | Yes | Yes | Yes | Yes |
| Supervisors | Yes | Yes | Yes | No |
| Secretaries | Yes | No | No | No |
| Other | No | No | No | No |
Figure 7.9
Table showing the rights on the Group table
Managers has all rights. Supervisors have update, insert and delete rights as the supervisor is supervising a group of staff and decides who should belong to which group of staff and so forth. Secretary has rights to update group details in case any changes are made but not to insert or delete. The other employees have no rights.
7.10 Managing Security
These security factors can be changed or altered on implementation of a particular design. Each user gets an account and password regardless of what DBMS design is implemented. These tables are used to determine privilege granting to each users depending on which group of staff they belong to. Queries on data will depend on who is accessing the data and what privilege rights they have. An example of security rights given next.
If an employee wishes to update a property; than only properties that the employee is dealing with will be shown and not other data. A query such as below may be an example:
Step 1
Firstly a view is created (which is updatable) which allows the employee to view their own specific data. For example employee with ID number 13.
CREATE VIEW EMPLOYEE_13
SELECT PROPERTY.* FROM EMPLOYEE E, MANAGES M, PROPERTY P
WHERE E.EMP_NO=M.EMP_NO
AND M.PRP_NO = PRP.PRP_NO;
Step 2
Then grant permission on the view EMPLOYEE_13 all the properties on user id. Conforming to the PROPERTY security table.
GRANT UPDATE, INSERT, DELETE
ON EMPLOYEE_13 TO "User_ID"
8 Backup and Recovery
We have not included backup in our designs as this will increase the costs of our designs. When you choose a particular design we will be able to implement this factor. Back up will allow recovery of data in the event of failure. In centralized database system is less complex to backup and recover data than distributed database systems due to the fact that data is stored at 3 different sites and is fragmented so it is complicated to backup the correct data.
Backup is important to ensure the availability of the database system after a database or hardware failure. Backup files needs to be stored at a predetermined site. It could include the following procedures for all 3 designs [REF 9]:
9 Costing
This section describes the costs of each of the three designs should you decide to implement one of the systems. Before we go into detail about hardware and software costs a general description of the economics of the three designs will be given. This will assist you in determining what might be suitable for your company. It will provide you with an idea of costs involved with each of the systems. If you do decide to pick a particular system we will provide a more detailed account of the costs of that design. The contents of this section involves; general economics, software, hardware, staff and installation costs.
9.1 Economics
There are three main costs involved with each system. These are shown in figure 9.1 below. The RDBMS and OODBMS design both have high communication costs but, low operating and maintenance costs. Communication costs are high due to the data having to be transferred from the main site in London to sites in Glasgow and Cardiff. However since there is only one site and not three sites where the database is located, the operating and maintenance costs are low. For the DDBMS designs the communication costs are average. That is depending on which site the data is being accessed from i.e. off-site or on-site. The operating costs is average as there is more sites required to be used i.e. 3 sites. Because of this the maintenance costs (i.e. maintaining the three sites for any errors occurring, breakdowns that may occurred and so on) are high.
| Design | Communication | Operating | Maintenance |
| RDBMS | High | Low | Low |
| DDBMS | Average | Average | High |
| OODBMS | High | Low | Low |
Figure 9.1
Table showing a typical costs in each of the designs
The costs of the three designs are divided into three sections shown below.
All prices include VAT currently at 17.5%.
9.2 Hardware
Requirements involved devices and equipment to drive the DBMS. The hard disk is required to store the DBMS on a permanent basis. More hardware are required for multi-user networked system in which communications lines link each users’ workstation to the main server. Networking within a company or building is carried out via a LAN. Below is an account of the main hardware requirements for your company. It includes costs and specification of each of the components.
9.2.1 Personal Computers
Your requirement of 200 PCs for your 300 staff based at the three sites. We have picked a system which is upgradable and should suit your needs i.e. cutting out unnecessary specifications which your company does not require such as 3D wavetable sound and so on. We are solely concerned with meeting your business needs for now and the future. This requirement is the same for all three designs. The computers will be divided into 60 computers at the Glasgow and Cardiff site but 80 at the main head office in London. The costs is shown below with the specification.
| Design | Cost per unit (�) | Number of units required | Total Costs (�) |
| All | 1311 | 200 | 262,200 |
Figure 9.2
Table showing the costs of the PCs [Ref 7]
Specification
Pico Computers:
Spider Triton II Intel Motherboard 512K, Pentium 200MMX Chip, 32MB 60ns EDO RAM, 2.5GB EIDE Hard Disk, x24 CDROM Drive, 1.44MB Floppy Drive, Smile 15" 0.28mm Monitor, 1MB 64 Bit Cirrus Logic 5446 Video Card, Keyboard and Mouse, High Tower Case with 5 Drive bays, 32 Bit Network Card, Microsoft Windows NT, Microsoft Office 97.
9.2.2 Servers/Workstations
These will deal with communications coming to and from the sites. In the DDBMS there are three work stations one for each site and in the RDBMS and OODBMS there is one main fast server. This is shown in figure 9.3 below.
| Design type | Hardware | Number of units required | Costs per unit (�) | Total Costs (�) |
| RDBMS | Micron Vetix MXI Server | 1 | �5000 | �5000 |
| DDBMS | Micro ClientPro XLU | 3 | �1656 | �4967 |
| OODBMS | Micron Vetix MXI Server | 1 | �5000 | �5000 |
Figure 9.3
Table showing the costs of servers required [Ref 1]
Specification
Micro Clientpro XLU:
Intel 266MHz Pentium II MMX processor; 32MB EDO RAM; 2.1GB SMART hard drive; 17" Micro 700fgx; 0.26dp; 512 KB Internal L2 secondary cache; DMI support; 3.5" floppy drive; 16x EIDE variable speed CDROM; 3Com PCI 10/100 Ethernet NIC; PCI 64-bit 3D video; MPEG; 4MB EDO RAM; Microsoft IntelliMouse; Microsoft Windows NT Workstation; Intel LANDesk Client Manager.
Micro Vetix MXI Server:
Intel 200MHz Pentium Pro processor; 128 MB ECC EDO RAM; Three 4GB Ultra-Wide SCSI-3 hard drive (12GB total); Dual Pentium Pro ZIP sockets; 256KB integrated L2 cache; 8 open expansion slots: 5PCI; 2 ISA; 1 shared ISA/PCI; Integrated Adaptec PCX Ultra-Wide SCSI-3 controller; Integrated Intel EtherExpress Pro 100 controller; 12X variable speed SCSI CD-ROM; 5 internal hot swappable hard drive array bays; 3 external 5.25" media bays; x1 330 watt power supply standard; Microsoft Windows NT Server 4.0
Intel LANDesk Server Manager 2.52.
9.2.3 Hubs
These will connect the computers together so that they may communicate with the outside world as well as internally. Fast Ethernet hubs are used for optimizing network performance. 10 are required 3 at the Cardiff and Glasgow sites and 4 at the London site. The costs are the same for all three designs.
| Design | Cost per unit (�) | Number of units required | Total Costs (�) |
| All | 1352 | 10 | 13,520 |
Figure 9.4
Table showing the costs of the Hubs [Ref 5]
Specification
Intel Express Standalone Hub:
100Mbps Fast Ethernet connections for up to 24 PCs Easy to use; Cost Effective; 10x increase performance over traditional 10BaseT; Comprehensive array of LEDs for immediate overview of network’s performance; Auto partitioning for faulty NICs until repaired; Auto correction of polarity at hub.
9.2.4 Routers
Routers are required for secure networking over the Internet. The costs are the same for all 3 designs
| Design | Cost per unit (�) | Number of units required | Total Costs (�) |
| All | 728 | 3 | 2184 |
Figure 9.5
Table showing the costs of the Routers [Ref 5]
Specification
Virtual Private Network [VPN]:
Secure LAN to LAN connectivity over the Internet featuring 144 bit encryption; Multiple protocol support including Frame Relay; X.25; EurolISDN and PPP; Easy configuration and management with Intel Device View for Windows; Utilizes the comparatively low cost of the Internet for WAN linking; Various models offering PPP; Multilink PPP; L:APB; X.25 or Frame Relay.
9.2.5 Miscellaneous
This includes all other general hardware requirements. For example cables i.e. network cables costs are about �2-4 per meter. Costs would be of about �5000 for all three designs.
9.2.6 Printer
One main printer is required at each site for exceptionally fast mono printing. The costs are the same for all 3 designs.
| Design | Cost per unit (�) | Number of units required | Total Costs (�) |
| All | 925 | 3 | 2775 |
Figure 9.6
Table showing the costs of the printer [Ref 2]
Specification
Oki OkiPage 16n Office Laser:
Fast output; 600 dpi mono based LED based engine; 16 ppm; 32 MHz MIPS R3000 Processor; Network connectivity
9.2.7 Printer Server
This is required for the laser printer at each site to link the computers to. It is called the Network Express Pro 100. The costs are the same for all 3 designs.
| Design | Cost per unit (�) | Number of units required | Total Costs (�) |
| All | 253 | 3 | 759 |
Figure 9.7
Table showing the costs of the Printer Server [Ref 5]
9.2.8 Total Costs
The total cost of each of the design in terms of hardware is shown in figure 9.8 below.
| Design | Total Costs (�) |
| CRDBMS | 291438 |
| DRDBMS | 291406 |
| COODBMS | 291438 |
Figure 9.8
Table showing the total costs of the hardware requirements for each design
The different between each design is small. This is due to factors such as the server and software determining the main differences. The next section will discuss your software requirements needs.
9.3 Software
This section describes the software requirements for your company. This includes the DBMS, an operating system, and one or more application programs. As the database are used by many users (multi-user) a networking configuration is required, including a communication control program (CCP) or a multi-user package. The choice of software we have proposed for this system is ORACLE 8.0 Server for the RDBMS and DDBMS. Oracle is an extremely well tried and tested software. The GemEnterprise package for the OODBMS should allow you to access remote sites and transmit queries and data among the various sites via a communication network; Keep track of the data distribution and replication in the OODBMS catalog; Has the ability to devise execution strategies for queries and transactions that access data from more than one site; Has the ability to decide on which copy of a replicated data item to access; Has the ability to maintain the consistency of copies of a replication data item; Ability to recover from individual site crashes and from new types of failures such as the failure of a communication link
9.3.1 Commercial
The software requirements for each database design is described below in figure 9.9.
| Design | Software | Cost per unit (�) | Number of units required | Total Costs (�) |
| RDBMS | Oracle 8 Server | 860 | 1 | 860 |
| DDBMS | Oracle 8 Server | 860 | 1 | 860 |
| OODBMS | GemEnterprise 2.0 | 1565 | 1 | 1565 |
Figure 9.9
Table showing the costs of the commercial software [Ref 3,4]
Specification
Oracle 8 Server:
Easy to use; Excellent in terms of power/price/performance; Easy to use management tools
Full distribution replication; Web features which enable intranet computing; The replication and distributed data access features allows users to share relational data across applications and servers
GemEnterprise 2.0:
Production ready Smalltalk application server; Excellent block and commit performance Build scaleable replication servers in a distributed server environment; Remote object replication and synchronized modifications within a distributed server environment; Enables centralized access and control over widely distributed applications and information.
9.3.2 Total Costs
The total cost are as specified in figure 9.9.
9.4 Staff Costs
These costs involve the amount of staff required to install the database system during the period of the project for each design. The costs of the RDBMS and OODBMS are less than the distributed designs this is due to several reasons of which the main ones are listed below:
The staff costs are shown below in figure 9.10 below.
| Design Type | Cost (�) |
| RDBMS | 50000 |
| DDBMS | 60000 |
| OODBMS | 50000 |
Figure 9.10
Table showing the staff costs of each design
This staff costs are to ensure all the skilled and experience staff are used. This is to ensure that the project is completed on time and is up and running within the time constraints of the project.
9.5 Installation Plan
The steps that we will take from the initial start of the project to the final implementation and getting the database system on line is shown below:
The RDBMS and OODBMS designs will take 8 weeks and the DDBMS will table 12 weeks to complete. Steps that we will take are briefly described below.
9.5.1 Hardware requirements
9.5.2 Software requirements
9.5.3 System wide requirements
9.5.4 Cost of installation
This costs of installing the system from start to finish will be an additional �10000 for all three designs.
9.6 Total costs of each design
The total cost for each design is the sum of all the hardware, software, staff and installation costs discussed in sections 9.2-9.5 and is shown in figure 9.11 below.
| RDBMS | DDBMS | OODBMS | |
| Hardware Requirements | 291438 | 291406 | 291438 |
| Software Requirements | 860 | 860 | 1565 |
| Installation Plan | 10000 | 10000 | 10000 |
| Staff Costs | 50000 | 60000 | 50000 |
| Total Costs (�) | 352298 | 362266 | 353003 |
Figure 9.11
Table showing the total costs of the 3 designs
There is only a slight difference in the designs for the distribute being more higher costs due to the complexity of the DDBMS.
9.7 Summary
We feel that we have been cost effective and that because there is not much variation in the cost of each design this is to your advantage and you will be able to choose the design that you prefer more easily. The next section will now describe the comparisons of the 3 designs.
10 Comparisons of three designs
This section covers different areas for comparing the three designs. It is done to give you a more clearer idea of the differences between the designs and which ones are better in some areas and worse in other.
10.1 Communication Costs
Communication costs are a major factor in these three designs. Here we aim to explain to DreamHome why there are differences in these three designs and which would be the most ideal solution we would suggest. Communication is essential the cost of transferring the data over the network that is why we are suggesting a high -performance local are network in our designs. This involves optimizing the queries to reduce the amount of bytes of information that have to be transferred over the network. This can only be achieve to intense scrutiny of the queries to be used and in practice. The first and last designs are centralized therefore would be based at one main site from which other branches would be able to access the information from. This incurs one. The second design is distributed i.e. has certain data allocated at different sites. A table below shows simply the effect of communication costs on the 2 different types.
| DBMS Type | Communication Costs |
| Centralized | High |
| Distributed | Low |
Figure10.1
Table showing the typical communication costs
between centralized and distributed designs
Taking into account the fact that centralized database system has to be accessed by other branches from around the country communication costs for updates and reading would be high where as if the locality of reference is nearer to each branch the costs incurred would be lower. A solution we suggest would be to have a distributed database system as the cost of remote access would be lower.
10.2 Locality
With centralized DBMS the first and last design of which are of this type causes the locality of reference factor to be low. This is due to the other three branches having to access data required from in one site unless the branch itself is that site. With the distributed design this factor is high as relevant data is located at each of the three branches dealing with the different areas of Britain.
| DBMS Type | Locality of Reference |
| Centralized | Low |
| Distributed | High |
Figure 10.2
Table showing the locality
between centralized and distributed designs
10.3 Reliability and Availability
With centralized DBMS the problem with reliability (probability that a system is up at a particular moment) and Availability (probability that the system is continuously available during a time interval) is low. For distributed designs this value is high. This is because should one site fail for example in London the Glasgow and Cardiff sites should still be operating and should not affect the entire network. If centralized database system if the site fails the whole system is not available to all users.
10.4 Storage Costs
Storage costs for the centralized DBMS are lower than DDBMS as slightly more data is stored in DDBMS databases and three different sites are required with different levels of fragmentation.
10.5 Performance
The performance in centralized databases are lower than distributed DBMS as shown below.
| DBMS Type | Performance |
| Centralized | Low |
| Distributed | Average |
Figure 10.3
Table showing performance difference between
centralized and distributed designs
Because the DDBMS is distributed over several sites i.e. the 3 branches. This will result in local queries and transactions accessing data at a single site have a better performance. Each site has a smaller number of transactions executing that if all transactions are submitted to a single centralized database. Transactions across access over more than one site , processing at the different sites may proceed in parallel reducing the response time.
10.6 Other
Here is a table which shows a comparison between object and relational database design adapted from Ref. 10. This will give you an idea on how there are differences in the structure between the two databases.
| Relational Databases | Object Oriented Databases |
| Primary goal: data independence | Primary goal: encapsulation |
| Data only: The database generally stores data only | Data plus methods: The database stores data plus methods. |
| Data sharing: Data can be shared by any processes. | Encapsulation: Data can only be used by methods of classes. |
| Data Independence | Class Independence |
| Simplicity | Complexity |
| Separate tables | Interlinked data |
| Nonredundant data | Nonredundant methods |
| Different conceptual model | Consistent conceptual model |
Figure 10.4
Table showing the caparisons between object and relational database designs
There are differences in the hashing techniques between OODBMS and RDBMS [Ref. 1]. RDBMS clusters records from 1 relation followed by the related records from another relation so that the related records may be retrieved in the most efficient way possible. In OODBMS it provides persistent storage for complex structured objects. Using indexing to locate disk pages that store the object. Objects are reconstructed after copying the disk pages that contain the object into system buffers. In DDBMS the technique is similar to RDBMS.
Common processes in RDBMS get replicated across different application causing productivity and maintenance. In OODBMS redundancy is decrease by use of inheritance and allows for reuse of classes and lowers the cost of development and maintenance. Triggers fro example, as discussed in section 3 is executed by the RDBMS but are still separate from the processing that goes on. In OODBMS we could make the trigger associated with the entity as we have done in the OODBMS design.
11 Future Improvements
Example of future improvements on the design are discussed here. On implementation of a particular design we can further optimize and improve our designs to ensure it meets with your requirements. For example, query optimization. This would depend on the costs of executing a query using different execution strategies. The lowest cost estimate being the one to aim for. An optimization technique, such as dynamic programming, may be used to find the optimal (least ) cost estimate efficiently without having to consider all possible execution strategies. Replication over the three sites could be determined more effectively. Maximizing the performance of your queries can be at the expense of disk storage space and reduced performance of INSERT, UPDATE and DELETE operations. We would need to strike a balance to your needs and requirements. We would need a detailed account of who is allowed to use the database and view particular data in order to give a secure companies performance and economics and soon. We would need to know which system you would accept. So that when we implement the system we can optimize all the many functions to suit your company’s needs. For example, indexes database. General processing and optimization of the queries would need to be done to reduce any costs and so on.
Other improvements could be if you wanted to have images on the properties stored in the database then you would be better off choosing the OODBMS designs. This is because the OODBMS is more suitable for handling BLOBs (Binary Large Object) such as images [Ref. 10]. Also other suggestions we would make is to make your company available on the internet. Advertising yourself will bring extra business and provides the means to communicate with your clients.
12 Conclusion
In all the 3 designs we have done the best we can in giving you an idea of the kind of data that is stored, transactions that may take place, provided you with detailed analysis of security and costs and given you a comprehensive comparisons of the three designs. We hope our report will enable you to choose one of our designs.
When you do decide to choose one of the designs we will than be able to concentrate more effectively on the design of your choice and make further improvements and more extensive analysis of the problem., as well as improve on and adding the logical. The physical design can be improved on once we know what software and hardware we will install in your company.
If you have any further queries with regards to any of the database design or any other general queries pleased do not hesitate to contact us at DAC.
12.1 Our Strengths
We would like this opportunity to tell you about our strengths in why you should choose one of our designs.
13 Bibliography